# Аналіз предметної області
# Вступ
В даному документі проведено аналіз предметної області системи управління відкритити даними. Розглянуто основні визначення термінів та скорочень, які використовуються при аналізі предметної області. Описано підходи, моделі та способи вирішення завдання. Перелічено існуючі програми, інформаційні системи, сервіси, що призначені для вирішення завдання. Зроблено висновки щодо доцільності розробки нової інформаційної системи управління відкритими даними.
# Основні визначення
Відкриті дані — це концепція, за якою певні дані мають бути вільними для використання та розповсюдження будь-якою
особою з будь-якою метою. Відкриті дані мають бути ліцензовані. Ліцензія повинна дозволяти людям використовувати
дані будь-яким способом, у тому числі трансформувати, поєднувати та ділитися ними з іншими, навіть у комерційних цілях.[1]
Предметна область (бази даних) — це сфера застосування конкретної бази даних. Наприклад, медицина, освіта, залізничний транспорт тощо.[2]
Big Data (великі дані) – це поєднання структурованих, напівструктурованих та неструктурованих даних, які можуть бути видобуті для отримання інформації та використані в проектах машинного навчання, прогнозного моделювання та інших передових програм аналітики.
Big Data часто характеризуються такими характиристиками (англійською – 3 V):
- великий обсяг даних (Volume)
- широкий вибір типів даних, що зберігаються в системах великих даних (Variety)
- швидкість, з якою дані генеруються, збираються та обробляються (Velocity)[3]
База даних (Database) — це організований набір структурованої інформації або даних, які зазвичай зберігаються в електронному вигляді в комп’ютерній системі.[4]
Система управління базами даних (DBMS - database management system) - системне програмне забезпечення для створення та керування базами даних. СУБД дозволяє кінцевим користувачам створювати, захищати, читати, оновлювати та видаляти дані в базі даних.[5]
Моделі даних (Data models) — це візуальне представлення елементів даних підприємства та зв’язків між ними. Допомагаючи визначити та структурувати дані в контексті відповідних бізнес-процесів, моделі підтримують розробку ефективних інформаційних систем. Вони дозволяють бізнес-ресурсам і технічним ресурсам спільно вирішувати, як дані зберігатимуться, отримувати доступ, надавати спільний доступ, оновлювати та використовувати в організації.[6]
Банк даних (Data bank) — це добре організований і підтримуваний набір даних для легкого перегляду та використання. Це сховище даних доступне на локальних і віддалених серверах і може містити інформацію про один, виділений предмет або кілька предметів у добре організований спосіб.[7]
Набір даних (Data set) — це набір або колекція даних. Цей набір зазвичай представлений у вигляді таблиці. Кожен стовпець описує певну змінну. І кожен рядок відповідає певному елементу набору даних відповідно до заданого запитання.[8]
Штучний інтелект (ШІ) - розділ комп'ютерної лінгвістики та інформатики, що опікується формалізацією проблем та завдань, які подібні до дій, що виконує людина. [9]
Natural Language Processing (NLP) - з англійської "Обробка природньої мови". Загальний напрям інформатики, штучного інтелекту та математичної лінгвістики, що вивчає проблеми комп'ютерного аналізу та синтезу природної мови.[10]
NLP-анотація - процес додавання міток метаданих до набору текстових даних для його подальшого опрацьовування ШІ.[11]
# Підходи та способи вирішення завдання
# Види NLP-анотації
Залежно від напрямку опрацьовування текстів можливі декілька видів NLP-анотації текстів.
# Анотація за емоційним забарвленням
Оцінює ставлення та емоції, що стоять за текстом, позначаючи цей текст як позитивно, негативно або нейтрально забарвлений.
Оцінка емоційного забарвлення тексту - одне з найважчих завдань у NLP, адже у різних контекстах одне і те ж слово може виражати різні емоції. Тому дуже велике значення мають правильно підібрані дані для навчання. Зазвичай використовувані тексти розбивають на невеликі уривки, тональність яких можна оцінити за однією з існуючих шкал.[12] В сучасних системах автоматичного визначення емоційної оцінки тексту найчастіше використовується одномірний емотивний простір: позитив чи негатив (добре або погано). Однак відомі успішні випадки використання і багатовимірних просторів.
Основним завданням в аналізі тональності є класифікація полярності даного документа, тобто визначення, чи є виражене думку в документі або пропозиції позитивним, негативним або нейтральним. Більш розгорнуто, «поза полярності» класифікація тональності виражається, наприклад, такими емоційними станами, як «злий», «сумний» і «щасливий».
# Класифікація за бінарною шкалою
Полярність документа можна визначати за бінарною шкалою. У цьому випадку для визначення полярності документа використовується два класи оцінок: позитивна чи негативна. Одним з недоліків цього підходу є те, що емоційну складову документа не завжди можна однозначно визначити, тобто документ може містити ознаки позитивної оцінки, так і негативної ознаки. Ранні роботи в цій царині включають в себе праці Терні і Панга, які застосовують різні методи розпізнавання полярності оглядів товару і відгуків про фільмах відповідно. Це приклад роботи на рівні документа.
# Класифікація за багатосмуговою шкалою
Можна класифікувати полярність документа по багатосмуговій шкалою, що було зроблено Пангом і Снайдером (серед інших). Ними було розширене основне завдання класифікації кіно-відгуків від оцінки «позитивний або негативний» в бік прогнозування рейтингу по 3-х або 4-бальною шкалою. У той же час Снайдер провів поглиблений аналіз оглядів ресторанів, пророкуючи рейтинги їх різних властивостей, таких як їжа і атмосфера (за 5-бальною шкалою).
# Системи шкалювання
Іншим методом визначення тональності є використання систем шкалювання, за допомогою чого словами, зазвичай пов'язаних з негативними, нейтральними або позитивними тональностями, ставляться відповідно числа за шкалою від -10 до 10 (від негативного до самого позитивного). Спочатку фрагмент неструктурованого тексту досліджується з допомогою інструментів та алгоритмів обробки природної мови, а потім виділені з цього тексту об'єкти та терміни аналізуються з метою розуміння значення цих слів.[13]
Після визначення емоційної тональності кожного з фрагментів можливо порахувати відсоткове значення кількості кожного з типів уривків у тексті та за потреби визначити його загальне забарвлення.[14]
# Анотація намірів
Анотація намірів аналізує мету, що стоїть за текстом, класифікуючи його за кількома категоріями, такими як запит, наказ або затвердження.
Класифікація намірів стала важливою зміною для бізнесу, особливо у поркащенні досвіду клієнтів. Chatboxes, наприклад, є популярною платформою, яка використовує розпізнавання намірів для аналізу розмов про продажі, підтримки клієнтів тощо. Автоматизація потреб в обслуговуванні клієнтів за допомогою класифікації намірів дозволяє підприємствам рости швидше та якісніше обслуговувати клієнтів. Враховуючі специфічну напрямленість ШІ для розпізнаваня намірів зазвичай анотують фрагменти діалогів та інші види "живої" мови.[15]
# Семантична анотація (NER-розмітка)
Семантична анотація додає різні теги до тексту, які посилаються на поняття та сутності, такі як люди, місця чи теми.
# Токенізація
Перед анотуванням, яке має виконувати людина, текст можливо розбити на сутності (токени) для полегшення процесу. Таким чином анотатору потрібно буде лише категорізувати сутності, а не шукати їх. Токенізація виконується шляхом розбиття тексту на речення за розділовими знаками, а речення - на токени за допомогою регулярних виразів (opens new window). [16]
Named Entity (NE) — це назва, яка вказує на певну унікальну сутність. До сутностей належать імена осіб, назви місцевостей, організацій, творів, веб-сайтів і т.і. Сутність складається з одного або декількох слів, а також може містити пунктуацію (лапки чи коми). Більшість сутностей починається зі слова з великої літери, хоча сутності можуть містити і слова з маленької літери (Маркіз де Сад, Кримінальний кодекс України, поліклініка №3, народний депутат, червень 2020 р.). Бувають також випадки, коли допущена помилка написання або весь текст приведений до одного регістру.[17]
# До іменованих сутностей не належать і, відповідно, не виділяються:
- загальні іменники, які з тих чи інших причин написані з великої літери;
- назви хвороб, сортів рослин, тварин та інші назви, які пишуться з маленької літери (але помилково можуть також бути написані з великої літери);
- нові власні іменники, які стали загальновживаними: "компанія Facebook" (Facebook - це сутність), "у своєму Фейсбуку" (тут Фейсбуку - це вже не сутність);
- прикметники або іменники, які є похідними від іменованих сутностей: кіровоградський, УДАРівці, СБУшник (однак, різні відмінки одного й того самого іменника залишаються сутностями - наприклад, у словосполученні "Наташина мама" Наташина — PERS).
# Загальні правила анотації
- Одна сутність має бути неперервною: Тарас Шевченко, а не окремо Тарас і Шевченко, Тернопільска міська рада.
- Різні сутності, що стоять поряд, мають бути виділені окремо. Приклад: "спікер Верховної Ради Гройсман" - тут спікер — це окрема сутність типу JOB, Верховної Ради — це окрема сутність типу ORG, Гройсман — окрема типу PERS.
- Якщо назва повністю знаходиться в лапках (приклад: "картина «Ніч на Дніпрі»", "картина" не є частиною сутності), то виділяти її без лапок (тільки слова). Якщо ж назва містить слово в лапках, то виділяти також і лапки (приклад: Школа-інтернат "Барвінок", ТОВ «Саланг» — всі слова входять до сутності).
- Якщо одна сутність є частиною іншої (як правило, це стосується географічних назв), то додатково виділяти її не треба ("картина «Ніч на Дніпрі»": Ніч на Дніпрі — це сутність типу ART, слово Дніпрі окремо не виділяємо). Винятком є сутності DOC котрі містять в собі дату договору/документу як невід'ємну частину назви документа, а також сутності типу PERIOD які можуть містити в собі також дві окремих дати.
- Деякі абревіатури у межах сутності можуть закінчуватися крапкою. Якщо крапка позначає також кінець речення, непотрібно її захоплювати. Якщо ж абревіатура з крапкою трапляється посеред речення, то варто захопити. Наприклад: "... від 10 млн грн. до 15 млн грн."
- При анотації дуже важливо дотримуватись однакових підходів до виділення та класифікації подібних сутностей, бути уважними і педантичними. [18]
Тип проекту та пов’язані випадки використання визначатимуть, яку техніку текстових анотацій слід вибрати.[11]
# Модель даних DDF
DDF - це модель даних для спільної гармонізації багатовимірної статистики.[19]
- Модель даних DDF - це модель даних, тобто вона описує спосіб організації даних та визначення того, як частини даних співвідносяться один з одним.
- Узгодження DDF може використовуватися для узгодження даних, тобто воно може поєднувати дані з різних джерел в інтегровані, послідовні та однозначні набори даних. DDF підтримує практичний робочий процес, який призводить до простого обслуговування та постійно зростаючої колекції порівнянних даних.
- Спільна робота DDF - це загальна модель даних у відкритих числах. Відкриті номери - це ініціатива збору та узгодження світових даних.
- Багатовимірна статистика DDF призначена для зберігання статистики з декількома вимірами. Наприклад, населення в країні та році, а також по країні, році, статі та віковій групі.
# Кожний DDF набор даних визначає 5 типів даних:
- Точки даних (data points)
- Сутності (entities)
- Метадані (metadata)
- Поняття (concepts)
- Синоніми (synonyms)
# Точки даних
Дані в DDF зберігаються в парах ключ-значення (Datapoints). Ключ складається з двох або більше вимірів, тоді як значення складається з одного показника.
# Сутності
Кожна сутність представлена унікальним ідентифікатором у стовпці домену сутності. Цей ідентифікатор є унікальним, але лише в межах домену сутності. Ідентифікатор не обов’язково має бути назвою сутності, але тим не менше має мати значення. Наприклад, ger - Germania, pol - Poland, nor - Norway.
# Метадані
У загальному випадку — це дані, що характеризують або пояснюють інші дані. Наприклад, значення «4352893» само по собі недостатньо виразне. А якщо значенню «4352893» зіставлено достатньо виразне ім'я «поштовий індекс» (що вже є метаданими), то в цьому контексті значення «4352893» більш осмислене — можна витягати інформацію про місцеположення адресата, що має даний поштовий індекс.
# Поняття
DDF має ряд заздалегідь визначених типів понятть. Поняття отримують тип шляхом встановлення властивості concept_type поняття. DDF також дозволяє визначити власні типи концепцій. Визначеними типами концепцій є:
- рядок (симовлів);
- міра (числове значення);
- інтервал (між двома числовими значеннями. Значення інтервалу - це два числа у форматі масиву JSON);
- логічне значення (boolean);
- домен сутності (поняття, яке має всі можливі значення);
- набір сутностей (концепція, у якій перераховані всі можливі значення, обмежені доменом сутності);
- роль (набір сутностей, який містить в точності ті ж сутності, що й інший набір сутностей. Отже, у ролі є інша сутність, встановлена в якості домену);
- композиція (представляє собою композицію двох або більше інших понять, які належать один одному);
- час (окремий випадок домену сутності. Поняття рік, місяць, день, тиждень та квартал є її окремими випадками).
# Синоніми
Синоніми - це рядок який дозволяє визначити поняття або сутність у набору даних. Множина синонимів містить ідентифікатори сутностей та понять зі їхними синонимами.
Синоніми використовуються для знаходження ідентичніх понятть та сутностей для їх гармонізації (тобто перекладу набора даних з одного простіру імен до іншого).[20]
# Приклади українських анотованих корпусів
- Векторні представлення слів розмірністю 300 побудовані за алгоритмами word2vec, lexvec, GloVe. Для побудови лематизованої версії було використано словник ВЕСУМ
- Корпус УберТекст містить 67496871 речень, що включать 665 мільйонів токенів. Джерела речень: тексти періодичних видань, вікіпедії, художня література. Окрім узагальненого корпусу (та його токенізованої версії) ми також надаємо доступ до його частин
- Корпус законів та нормативно-правових актів, що містить майже 580 мільйонів токенів
- Корпус NER-анотацій містить 229 текстів з українського браунівського корпусу на 217 381 токенів з 6 751 розмічених NER-сутностей
- Тональний словник містить приблизно 3,5 тисячі базових форм слів ненейтральної тональності
- Збірник газетірів містить набори назв, такі як марки автівок, вантажівок, мотоциклів, човнів, а також назви країн[21]
# Порівняльна характеристика існуючих засобів вирішення завдання
# Doccano
# https://doccano.herokuapp.com
– це інструмент для розробки текстових анотацій. Він надає функції класифікації тексту та позначення послідовності завдань. doccano надає можливість створювати дані з мітками для аналізу настроїв, розпізнавання іменованих об’єктів, підсумовування тексту тощо.
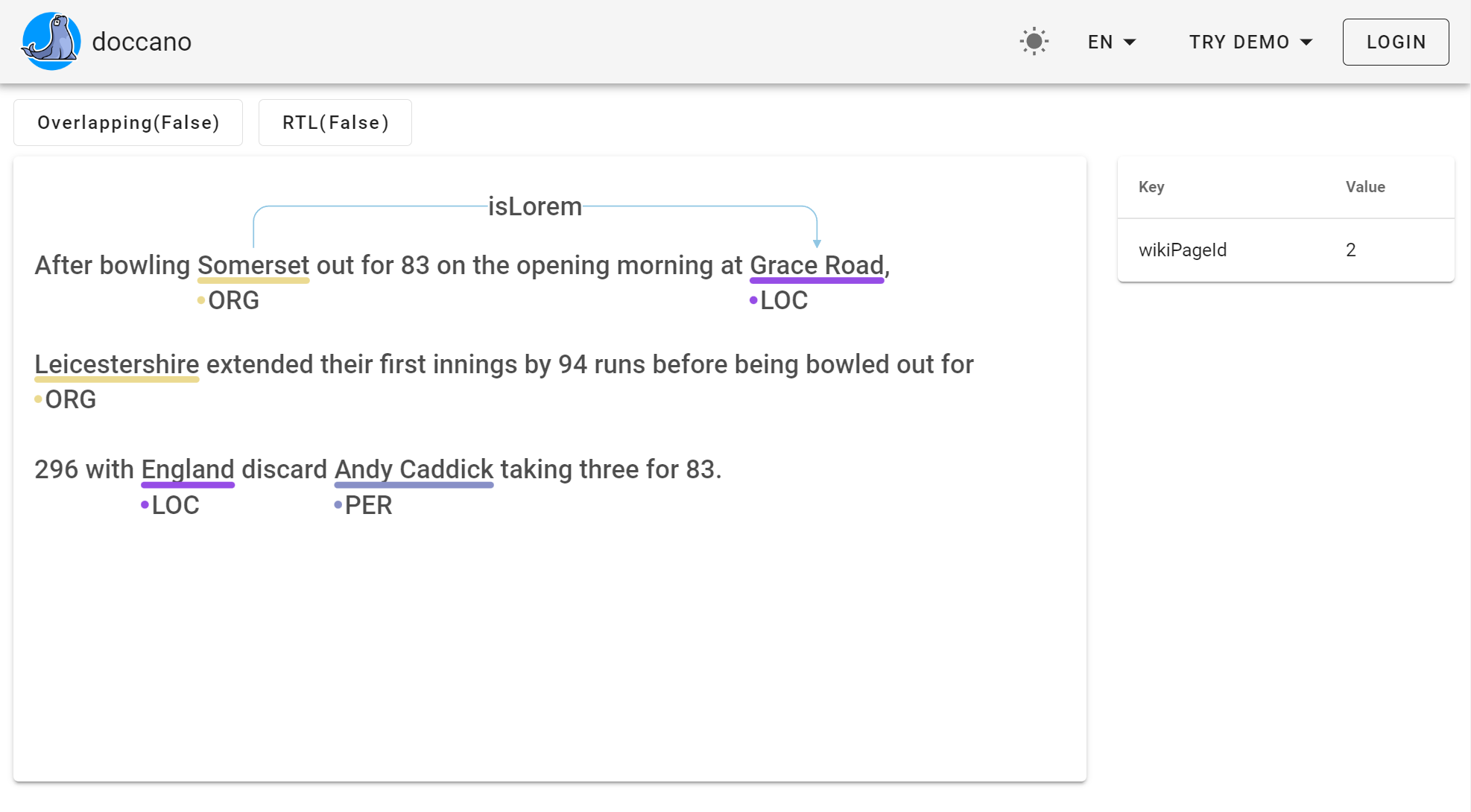
Функціональна частина програми дозволяє працювати з розпізнаванням сутностей, аналізом настроїв, перекладом, пошуком намірів та багато різних додаткових опцій.
# LightTag
# https://www.lighttag.io
– це інструмент для керування проектами для створення текстових анотувань, призначений для прискорення та покращення результатів ініціатив із обробки великої кількості тексту.
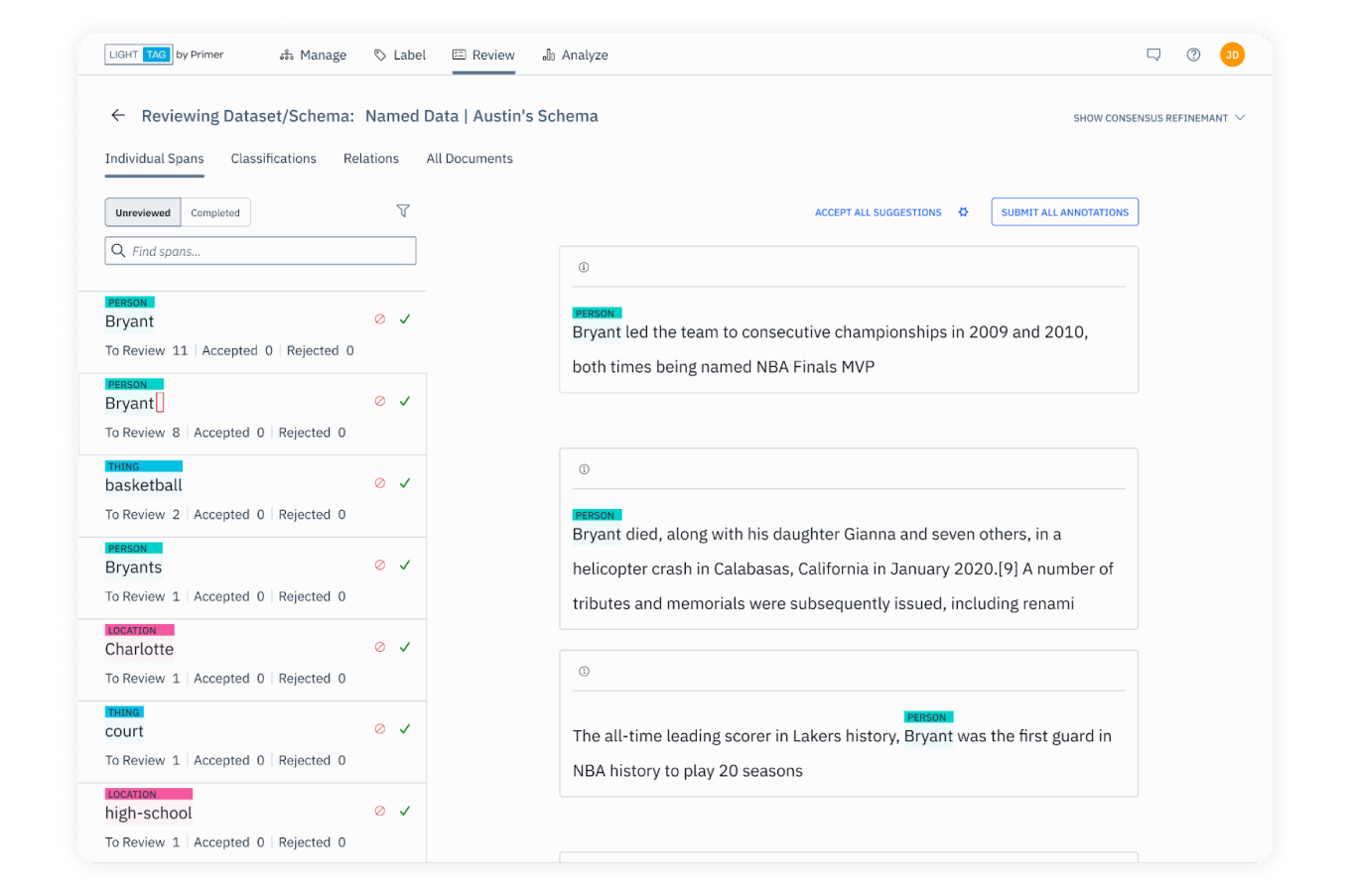
Програма пропонує великий спектр різноманітних інструментів для створення та обробки текстових анотацій. Також там є дуже зручні можливості задля праці з повноцінною командою (на зображенні).
# Prodigy
# https://prodi.gy
– це настільки ефективний інструмент для створення анотацій з різноманітними сценаріями, що дослідники даних можуть самостійно робити анотації, забезпечуючи новий рівень швидкої ітерації.
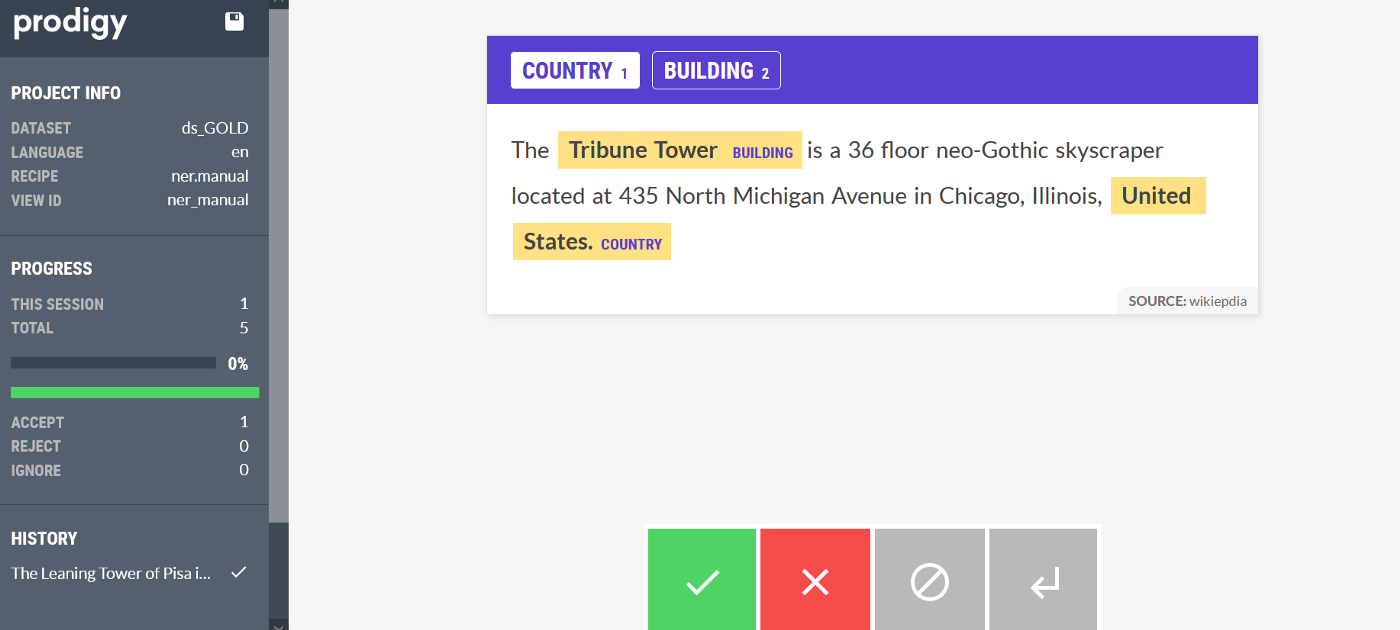
Окрім дуже зручного інтерфейсу, програма дозволяє користувачам налаштовувати і перепрограмовувати ії як завгодно, маючи повністю гнучкий та відкритий код.
# Dandelion API
# https://dandelion.eu
– надає різноманітні автоматичні інструменти текстових анотацій. Хоча це відносно нова компанія-стартап, їхні інструменти можна використовувати для вилучення сутностей, аналізу настроїв і класифікації тексту та його вмісту.
Програма є достатньо новою, але дуже перспективною. Розробники регулярно оновлюють актуальну версію, розширюючи функціональні здібности інструмента.
Порівняльна характеристика властивостей FURPS:
- Functionality (функциональні вимоги): Безкоштовна версія - API
- Usability (вимоги до зручності роботи): Робота в браузері - Документація - Гарячі клавіши - Інтерфейс
- Reliability (вимоги до надійності): Ліцензування - Період існування - Відкритий код
- Performance (вимоги до продуктивності): Оптимізація - Робота в команді - Підртимка Unicode
- Supportability (вимоги до підтримки): Служба підтримки - Зворотній зв'язок - FAQ
| Сервіс/Показник | Our Service | doccano | LightTag | Prodigy | Dandelion | |
|---|---|---|---|---|---|---|
| Functionality | Безкоштовна версія | ✅ | ⚠️ | ⚠️ | ❌ | ⚠️ |
| API | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Usability | Робота в браузері | ✅ | ✅ | ✅ | ✅ | ✅ |
| Історія змін | ✅ | ❌ | ❌ | ❌ | ❌ | |
| Документація | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Багатомовність | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Гарячі клавіши | ⚠️ | ❌ | ✅ | ⚠️ | ❌ | |
| Інтерфейс | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Reliability | Ліцензування | ✅ | ✅ | ✅ | ✅ | ✅ |
| Період існування | ✅ | ❌ | ⚠️ | ⚠️ | ❌ | |
| Відкритий код | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Performance | Оптимізація | ✅ | ✅ | ✅ | ✅ | ✅ |
| Робота в команді | ✅ | ✅ | ✅ | ❌ | ❌ | |
| Підтримка Unicode | ✅ | ✅ | ✅ | ✅ | ❌ | |
| Supportability | Служба підтримки | ✅ | ❌ | ✅ | ✅ | ✅ |
| Зворотній зв'язок | ✅ | ⚠️ | ✅ | ✅ | ✅ | |
| FAQ | ✅ | ✅ | ❌ | ❌ | ✅ |
# Висновки
В результаті проведеного дослідження було розглянуто методи створенння NER-анотацій та проаналізовано наявні інструменти розмітки. Було виявлено, що усі з розглянутих систем мають певні недоліки, проте найкращий з доступних застосунків є LightTag. Тож, нашою командою було ухвалено рішення створити систему, яка б повністю реалізувала всі потреби користувачів та мала б відповідний функціонал. Крім того, жоден із із застосунків не має функціоналу гілок змін та перегляду їх історії. Це буде основною перевагою нашого застосунку.
# Посилання
2(https://step.org.ua/konspekt/base/tema1)
3(https://futurenow.com.ua/shho-take-big-data-velyki-dani/)
4(https://www.oracle.com/database/what-is-database/)
5(https://www.techtarget.com/searchdatamanagement/definition/database-management-system)
6(https://www.erwin.com/solutions/data-modeling/data-model.aspx)
7(https://www.techopedia.com/definition/6731/data-bank)
8(https://byjus.com/maths/data-sets/)
11(https://appen.com/blog/text-annotation/)
12(https://www.telusinternational.com/articles/an-introduction-to-5-types-of-text-annotation)
14(https://ioannotator.com/sentiment)
15(https://www.taus.net/resources/blog/intent-recognition-in-nlp)
16(https://github.com/lang-uk/ner-uk/blob/master/doc/tokenization.md)
17(https://en.wikipedia.org/wiki/Named-entity_recognition)
18(https://github.com/lang-uk/ner-uk/blob/master/doc/README.md)
19(https://open-numbers.github.io/ddf.html)
20(https://github.com/marchiani/UniversityBD)
doccano(https://doccano.herokuapp.com)
LightTag(https://www.lighttag.io)
Prodigy(https://prodi.gy)
Dandelion API(https://dandelion.eu)